拾起Reinforcement Learning的基础概念和算法,参考A (Long) Peek into Reinforcement Learning
Terminology
强化学习中有很多的术语和概念,初学时经常被搞得很懵逼,所以先从术语开始,把基础的概念理解好。
强化学习是一套框架,这套框架通用的描述一个可以执行动作的所谓Agent通过和环境的交互进行学习,框架图如下图所示:
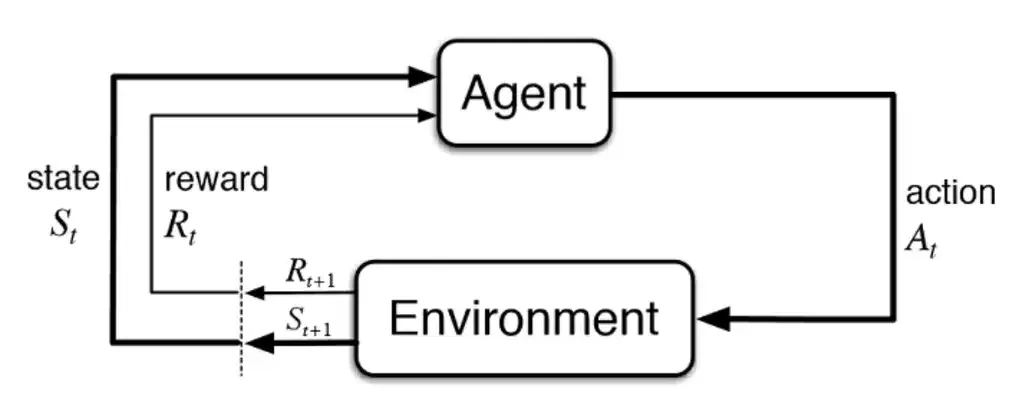
强化学习这套框架中充满了随机性,每一个概念几乎都是一个随机变量或概率密度函数,下面的开始的介绍中,简单规定一些符号:大写字母X表示随机变量,小写字母x表示随机变量的观测值,大写的P概率密度函数,花体字母S表示集合。不同的教材对下面的概念会采用相当不同的符号表示,例如David Silver的课程,UCB的课程等,不同的符号系统随着概念和算法的深入公式会变得更困难,因此坚持一套符号表示即可。
Basics
-
Agent:
Agent是环境中活动(执行动作)的主体,例如在真实世界中行驶的自动驾驶车(Ego Vehicle)。
-
Environment
环境或者现在的有些说法叫世界模型(World Model),是Agent所活动的环境的抽象。
-
State S:
状态指的是当前Agent所包含的信息,这些信息决定着Agent的未来。在某时刻t的状态St是一个随机变量,st是当前时刻的观测值,可以有很多可能的st。所有可能的状态的集合称为状态空间S,即State Space。
-
Action A:
动作指的是Agent采取的动作。在某时刻t的状态At是一个随机变量,at是当前时刻的观测值,可以有很多可能的at,这些动作可能是离散值,也可能是连续值。所有可能的动作的集合称为动作空间A,即Action Space。
-
Reward R:
奖励指的是Agent采取了动作环境给予Agent的奖励值。在某时刻t的状态Rt是一个随机变量,rt是当前时刻的观测值。奖励也会被称为奖励函数(reward function),环境根据当前的状态st和采取的不同动作at,会有不同的奖励值。
奖励也是一个很难的话题,因为RL是一个框架,Agent的目标是最大化未来的奖励,它塑造了Agent的学习目标和效率。很难有通用的奖励函数,一般是根据某个任务定义的,例如AlphaGo下棋,赢了得到了价值100的奖励,输了要惩罚100,这里奖励值的确定并没有科学的依据。例如在大语言模型应用强化学习进行RLHF,最大化的奖励是和人类对齐(alignment)的回答,但是模型也会出现Reward Hacking1。
RL算法也经常会面临奖励稀疏(Sparse Reward)的问题,导致RL比较大的问题是学习低效(inefficient),即需要超级大量的试错才能学到简单的动作。
- Return U:
回报的定义是累积的未来回报(Cumulative future reward),注意是未来:
Ut=Rt+Rt+1+Rt+2+Rt+3+⋯
由于未来时刻t的奖励和当前比不一定等价,所以打个折扣γ,也就是discounted return:
Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯
需要注意的是Ut是一个随机变量,它依赖于未来未观测到的奖励,而这些奖励依赖于未来采取的动作和状态,但是回报可以通过积分掉未观测到的变量获得期望值。
-
Trajectory:
轨迹是Agent与环境交互的序列:s1,a1,r1,s2,a2,r2,⋯
-
State Transition:
状态转移p(⋅∣s,a)指的是根据当前Agent的状态s和采取的动作a,环境转移到新状态s′的概率,因此状态转移时一个概率密度函数p(s′∣s,a)=P(S′=s′∣S=s,A=a)。
Policy Function
策略函数π是RL中最重要的概念之一,是指Agent当前的状态s映射到动作空间A内所有动作的概率分布,它控制Agent所采取的动作:
π(a∣s)=P(A=a∣S=s)
它是一个概率密度函数,所以有∑a∈Aπ(a∣s)=1。
Value Functions
价值函数同样也是RL中最重要的概念之一,主要有动作-价值函数,以及状态-价值函数,两者有密切关系。
两个价值函数都是由策略函数Policy控制的期望,期望就是对未来回报的平均预期,比喻来说就是Agent的“经验”。
Action-Value Function
动作价值函数Qπ(s,a),即经常见到的Q函数,描述了在给定状态s下采取某个动作a的好坏,这个好坏是通过代表未来累积奖励的回报Ut的期望来进行评价的:
Qπ(s,a)=Eπ(Ut∣St=s,At=a)
为什么是期望呢?因为未来(t+1时刻之后)可能采取的动作(由策略函数π(a∣s)控制)和进入的状态(由状态转移函数控制)都是概率饿分布,通过求期望,即通过概率加权求和或积分消掉未来的随机性,从而大体知道可以预期的平均回报是多少。
Keep in mind 期望E的本质是概率加权和,因此看到求期望的公式就要关注公式中随机变量和它的概率分布!
贝尔曼期望方程 (Bellman Expectation Equation) 以递归的形式定义了Qπ(s,a):
Qπ(s,a)=Eπ[Rt+γUt+1∣St=s,At=a]=Eπ[Rt+γQπ(St+1,At+1)∣s,a]=Eπ[Rt∣s,a]+γEπ[Qπ(St+1,At+1)∣s,a]=st+1∑p(st+1∣s,a)⋅rt+γst+1∑p(st+1∣s,a)at+1∈At+1∑π(at+1∣st+1)Qπ(st+1,at+1)=Est+1∼(⋅∣s,a)[Rt(s,a,st+1)+γVπ(st+1)]
其中,p(⋅∣s,a)是状态转移函数,在给定状态s和动作a的情况下,转移到下一个状态s′的概率分布。
注意,Qπ(St+1,At+1)和Qπ(s,a)是完全不同的,大写字母表示这是一个随机变量,随机变量的特定取值对应着概率。公式中有两个随机变量St+1和At+1,因此展开Qπ(St+1,At+1)先固定一个随机变量St+1通过状态转移函数,再对采样出的状态st+1下的所有at+1求和。
这是一个比较重要的推导(推导过程需要很小心),后面估计优势函数时会直接用到这个结论。
State-Value Function
状态价值函数Vπ衡量给定策略π,当前状态的好坏,相当于对动作价值函数Q,进一步积分掉所有的动作A:
Vπ(s)=Eπ[Ut∣St=s]=EA∼π(⋅∣s)[Qπ(s,A)]=a∈A∑π(a∣s)⋅Qπ(s,a)
状态价值函数描述了给定策略π现在所处的状态的好坏,不管采取什么动作。
Vπ(s)的贝尔曼期望方程:
Vπ(s)=Eπ[Rt+γVπ(St+1)∣St=s]
Optimal Value Functions
最佳动作价值函数(Optimal action-value function): Q∗(s,a)表示在策略函数π和状态s下采取动作a的最大预期回报:
Q∗(s,a)=πmaxQπ(s,a)
最佳状态价值函数(Optimal state-value function): V∗(s)表示在策略函数π中当前状态s的最大预期回报:
V∗(s)=πmaxVπ(s)
可以看到,两个最佳价值函数(Q∗(s,a)和V∗(s))都和策略函数π有关,即只要找到最佳的策略函数π∗(a∣s):
π≥π′ifVπ(s)≥Vπ′(s),∀s
对任意马尔科夫决策过程MDP有定理:
- 一定有一个最佳策略π∗(a∣s)好于或等于其他所有的策略
- 最优策略一定实现最优状态价值函数,Vπ∗(s)≥V∗(s),∀π
- 最优策略一定实现最优动作价值函数,Qπ∗(s,a)≥Q∗(s,a),∀π
RL算法的目标是最大化未来累积回报,可以看到,如果已知最优价值函数或最优策略,都可以实现RL这一目标,因此RL算法主要分为Value-based和Policy-based的方法。
Advantage Function
优势函数(Advantage Function)用于衡量在特定状态s下选择某个动作a相对于该状态下平均动作价值的好坏程度。其数学定义为:
Aπ(s,a)=Qπ(s,a)−Vπ(s)
直观的理解是“状态s下,动作a比平均水平(Vπ(s))好多少”。优势函数可以有效减少方差,因此广泛应用在PPO等算法中。
如何估计Advantage Function?通常都是使用Rollout出去的数据来估计Q函数,然后用神经网络来估计V函数
-
蒙特卡洛MC估计
用跑完一个完整回合的单条轨迹的累积回报作为Q(s,a)的估计,这条轨迹是一次无偏采样,但是蒙特卡洛算法估计的Q(s,a)存在方差高的问题,减去V(st)可以有效的降低方差:
Aπ(st,at)=k=t∑Tγk−trk−Vπ(st)
其中的V(st)可以由一个价值网络来估计。
-
时序差分(Temporal Difference, TD)估计
TD相比MC方法跑完一个整个回合,是一种边走边学,用“猜测”更新“猜测”的方法,它在一个回合的过程中,获得真实的reward,然后马上更新之前旧的预测。利用Q函数的贝尔曼公式:
Aπ(st,at)=Est+1[Rt+γVπ(st+1)]−Vπ(st)
TD误差的定义是:
δt=Rt+γVπ(st+1)−Vπ(st)
取条件期望:
Est+1[δt]=Est+1[Rt+γVπ(st+1)]−Est+1[Vπ(st)]
由于Vπ(st)在TD的语境下,此时是常数:
Est+1[δt]=Est+1[Rt+γVπ(st+1)]−Vπ(st)=Aπ(st,at)
通常使用单步TD估计,即走一步来估计优势函数,并且使用网络来估计Vϕ(s)来估计Vπ(s)函数即:
A^t(1)=(rt+γVϕ(st+1))−Vϕ(st)
这是一个有偏估计,非常依赖Vϕ(s)估计的准确性。
-
广义优势函数估计(Generalized Advantage Estimation, GAE)
对比单步TD,GAE是加权的k步估计,是目前最常用的且效果最好的优势函数估计,应用在PPO算法中。
At(1)^At(2)^At(k)^...At(∞)^=rt+γV(st+1)−V(st)=δt=rt+γrt+1+γ2V(st+2)−V(st)=δt+γδt+1=rt+γrt+1+γ2rt+2+⋯+γkV(st+k)−V(st)=δt+γδt+1+⋯+γk−1δt+k−1=rt+γrt+1+γ2rt+2+...−V(st)
At(1)^的偏差高,方差低,即TD;At(∞)^偏差低,方差高,即MC。上述公式通过TD Error可得At(k)^=∑l=0k−1γlδt+l,后续将使用TD Error继续推导。
GAE通过引入参数λ∈[0,1],并对At(k)^进行加权平均:
At^=A^tGAE=(1−λ)(At^(1)+λAt^(2)+⋯)=(1−λ)k=1∑∞λk−1At^(k)
λ的取值比较接近于1,可以看到At^(1)因为偏差比较大,所以对整体估计的贡献是比较少的,而越往后,估计的步数多的贡献越大,起到平衡平衡偏差和方差的作用。
为什么使用∑k=1∞(1−λ)λk−1? 因为它的和为1,可以自己展开公式推导一下。
使用TD Error δ来表示,并推导得到最终形式:
A^tGAE=l=0∑∞(γλ)lδt+l
递归形式:
A^tGAE=δt+γδA^t+1GAE
和前面的TD类似,通过使用网络Vϕ(s)来估计状态价值函数,再来计算GAE。
Policy-based Method
Policy-based方法,例如Policy Gradient,是直接建模策略函数π(a∣s;θ)来实现最大化未来累积回报的预期:
maximizeJ(θ)=Vπθ(S1)=Eπθ[V1]
其中,S1是初始状态。
期望累积奖励可以表示为平稳分布下的期望2:
J(θ)=s∈S∑dπθ(s)Vπθ(s)=s∈S∑(dπθ(s)a∈A∑π(a∣s,θ)Qπ(s,a))
其中,dπθ(s)称为平稳分布(stationary distribution)。
Policy Gradient
对上面的目标函数解析的求梯度(这里参考的是Wang Shusen的简化版):
∂θ∂J(θ)=∂θ∂∑s∈Sd(s)∑aπ(a∣s;θ)⋅Qπ(s,a)=s∈S∑d(s)a∈A∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)=s∈S∑d(s)a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)via∇f(x)=f(x)∇logf(x)=s∈S∑d(s)a∑π(a∣s;θ)∂θ∂logπ(a∣s;θ)⋅Qπ(s,a)vias∈S∑d(s)=1=EA[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]=EA[∇θlogπ(A∣s;θ)⋅Qπ(s,A)]
∇θJ(θ)称为策略梯度(Policy gradient),注意的是它是一个期望值,请记住这个公式。
Gradient Ascent
策略梯度算法使用梯度上升来更新参数(梯度下降用于最小化目标函数,对应的梯度上升用来最大化目标函数),伪代码如下:
- 从环境中得到状态st
- 从策略函数π(⋅∣st;θ)中随机抽样出at
- 计算qt≈Qπ(st,at) ← 下文回讲如何计算qt
- 求梯度: dθ,t=∂θ∂logπ(at∣st,θ)θ=θt
- (近似)计算policy gradient: g(at,θt)=qt⋅dθ,t ←这里是使用蒙特卡洛近似,只使用一次随机采样来估计policy gradient(回想一下policy gradient是期望)
- 更新模型参数:θt+1=θt+β⋅g(at,θt)
使用蒙特卡洛近似的方法对policy gradient是无偏估计,但是它的缺点是方差高。
还有一个问题:如何求Qπ(st,at)?使用REINFORCE方法:
- 使用当前的策略函数π执行直到结束,收集轨迹:s1,a1,r1,s2,a2,r2,⋯,sT,aT,rT
- 计算ut=∑k=tTγk−trk
- 因为Qπ(st,at)=E[Ut],我们使用ut来近似Qπ(st,at)
REINFORCE还有一个样本效率低的问题:执行当前策略πold收集到的轨迹后,更新参数得到了策略函数πnew,这时之前收集到的轨迹就完全没有办法使用了。REINFORCE属于严格的on-policy算法。
另外一个方法是使用一个网络来近似Qπ(st,at),这个就属于Actor-Critic方法了,在后面小节进行。
Policy Gradient with Baseline
前述使用MC采样的Policy Gradient算法的问题是方差较高,学者引入Baseline技巧,可以实现降低方差的作用。
首先来看一个推导:
======EA∼π[b⋅∇θlogπ(A∣s;θ)]b⋅EA∼π[∇θlogπ(A∣s;θ)]b⋅a∑π(a∣s;θ)[∂θ∂logπ(a∣s;θ)]via dxdlog(f(x))=x1f′(x)b⋅a∑π(a∣s;θ)[π(a∣s;θ)1⋅∂θ∂π(a∣s;θ)]b⋅∂θ∂∑aπ(a∣s;θ)b⋅∂θ∂10
b就是baseline,只要b和求导的参数θ以及动作a无关,它的期望就是0,所以把上式添加到Policy Gradient中,不改变Policy Gradient的期望值:
PG===EA[∇θlogπ(A∣s;θ)⋅Qπ(s,A)]EA[∇θlogπ(A∣s;θ)⋅Qπ(s,A)−∇θlogπ(A∣s;θ)⋅b]EA[∇θlogπ(A∣s;θ)⋅(Qπ(s,A)−b)]
其中,A(s,a)=Qπ(s,a)−b又称为Advantage函数。
但是为什么要加呢?虽然不改变期望值,但是在使用蒙特卡洛近似(随机采样at并计算gt)时,选择合适的baseline,可以降低方差。baseline的选择有很多,b可以为常数,更常见的选择是b=V(s),即A(s,a)=Qπ(s,a)−b=Qπ(s,a)−Vπ(s)。
直观的解释Advantange函数的话就是:
- A(s,a)>0,则表示当前动作a的回报优于平均值
- A(s,a)<0,则表示当前动作a的回报低于平均值
TRPO
TRPO全称是Trust Region Policy Optimization,是优化策略函数的方法,将数值优化领域的Trust Region优化巧妙应用到策略函数的优化。
Trust Region
单独拿出来Trust Region是因为这不是TRPO的发明,而是数值优化领域的算法,首先理解Trust Region的基础,可以更好的理解TRPO。这里推荐Wang Shusen老师的视频TRPO 置信域策略优化,非常清晰。
假设N(θold)是参数θold的邻域,即这个邻域内的参数距离θold在一定的距离之内,度量距离有多种选择,例如KL散度。
如果我们有一个函数,L(θ∣θold)在N(θold)内近似J(θ),那么称N(θold)为Trust Region。
Trust Region算法重复两件事情:
- Approximation: 给定当前参数θold,构建L(θ∣θold),它是在邻域N(θold)内对目标函数J(θ)的近似
- Maximization: 在Trust Region,更新参数θnew: θnew←θ∈N(θold)argmaxL(θ∣θold)
TR Policy Optimization
首先,重新改写目标函数J(θ),其中的技巧是重要性采样:
J(θ)=ES[Vπ(S)]=ES[a∑π(a∣s;θ)⋅Qπ(s,a)]=ES[π(a∣s;θold)⋅π(a∣s;θold)π(a∣s;θ)⋅Qπ(s,a)]=ES[EA∼π(⋅∣s;θold)[π(a∣s;θold)π(a∣s;θ)⋅Qπ(s,a)]]=ES,A[π(A∣S;θold)π(A∣S;θ)⋅Qπ(S,A)]
TRPO论文中是使用Advantage函数来替代Q函数的,公式推导和理解上差异不大,这里与Wang Shushen老师的课程中的公式一致。
在做重要性采样时,如果提议分布和目标分布差异过大,是没有办法进行优化的,因此我们假设的也是当前策略函数的分布θold和将要优化的策略函数的分布非常的近似,因此在Trust Region小步更新,更新步长太大也会造成优化不稳定。
下面开始应用Trust Region的两步(Approximation和Maximization)来优化目标函数:
Step 1. Approximation: 在参数θold的邻域内构建L(θ∣θold)近似J(θ)=ES,A[π(A∣S;θold)π(A∣S;θ)⋅Qπ(S,A)]
由于S和A都是状态和动作的随机变量,可以从状态转移函数和π函数中随机采样得到,使用π(A∣s;θold)和概率转移函数得到一组轨迹:s1,a1,r1,s2,a2,r2,⋯,sn,an,rn,这些轨迹点相当于是训练策略函数πθ的训练数据。
使用这组轨迹(蒙特卡洛)近似J(θ):
J(θ)≈L(θ∣θold)=n1i=1∑nπ(ai∣si;θold)π(ai∣si;θ)⋅Qπ(si,ai)
上式中,Qπ(si,ai)可以使用REINFORCE方法用roll out的轨迹进行估计,即ui,则:
L~(θ∣θold)=n1i=1∑nπ(ai∣si;θold)π(ai∣si;θ)⋅ui
Step 2. Maximization: 在Trust Region,更新参数θnew:
θnew←θ∈N(θold)argmaxL~(θ∣θold);s.t.θ∈N(θold)
这是一个带约束的优化问题,求解这个问题比较复杂,可以简单理解一个二阶优化问题,即使用到了Hessian矩阵。因此,后续PPO对此进行了改进。
PPO
近端策略优化算法是对TRPO算法的改进,TRPO有训练稳定的优点,但是使用二阶计算量较大。
PPO是对TRPO的改进,主要是对比较复杂的带约束的最优化问题进行了简化,可以使用一阶的优化算法进行,大大加快了效率。
我们回顾一下TRPO的带约束的优化问题:
θmaximizeE[π(a∣s;θold)π(a∣s;θ)Aπold(s,a)]s.t.E[DKL(πθold(⋅∣s)∥πθ(⋅∣s))]≤δ
PPO算法有两个变体,相对TRPO来说都很简洁,它们是PPOKLPEN和PPOCLIP,其中PPOCLIP效果更好,更常见。
PPO Penalty
PPOKLPEN,把约束项DKL放入到目标函数中去(有些类似拉格朗日乘子法),就变成了无约束的优化问题,这样就可以直接使用各种一阶优化算法了,例如SGD,ADAM:
E[π(a∣s;θold)π(a∣s;θ)Aπold(s,a)]−β⋅E[DKL(πθold(⋅∣s)∥πθ(⋅∣s))]
其中的β是一个自适应的调整项,需要一个作为超参数的dtarget,首先计算d=E[DKL(πθold(⋅∣s)∥πθ(⋅∣s))]:
- 如果d<dtarget/1.5→β=β/2
- 如果d>dtarget×1.5→β=β×2
PPO CLIP
PPOCLIP对Trust Region的进行了简化,通过控制重要性采样比率控制更新的补偿。令重要性采样比率为r(θ)=π(a;θold)π(a;θ),对r(θ)进行截断,并选择最小(“悲观”)的那一项:
LCLIP(θ)=E[min(r(θ)Aπold(s,a),clip(r(θ),1−ϵ,1+ϵ))Aπold(s,a)]
PPOCLIP是更常见的目标函数,论文的实验中也有更好的表现。
PPO论文作者在第5节中提到,很多方法会使用一个网络来估计advantage函数中的Vπ(s),如果policy网络和value网络共享参数,需要增加价值函数项LVF和熵奖励项(Entropy Bonus)S,写作:
LCLIP+VF+S=E[LCLIP(θ)−c1LVF(θ)+c2S[πθ(s)]]
其中的c1,c2都是超参数,其他两项:
-
LVF=(Vθ(s)−Vtarget)2,Vtarget可以通过广义优势估计(General Advantage Estimation, GAE)得到。
-
S[πθ(s)]=E[−πθ(a∣s)logπθ(a∣s)],这一公式是从熵的定义中来,熵越大表明信息量越大,目标函数鼓励这一项更大(因为使用的是+号),可以估计模型增加探索,因为π函数控制动作。
PPO的算法的实现3有非常多的细节和技巧,对于复现PPO算法很重要,有博客4总结了PPO实现的各种细节,会再另外一篇博客中单独叙述。
Valued-based Method
Value函数的定义即为对未来回报的期望,因此直接使用函数来近似动作/状态价值函数(Value Functions)称为基于价值函数的算法。
DQN
深度学习时代,经典的Deep Q Network就是使用深度网络Q(s,a;w)来近似动作价值函数Q(s,a),并用来控制Agent的动作:
at=aargmaxQ(st,a;w)
每次贪心地选择最大化价值的动作,则得到最佳动作-价值函数Q∗(s,a)。
我们不对DQN的网络做过多解读,举一个简单的打马里奥的例子,游戏的动作动作是A=[left,right,up],网络的输入是当前的图像,输出是每个动作的价值,例如[200,100,150],每次选择最大价值的动作。
Temporal Difference
如何训练DQN呢? 一般使用TD Learning进行训练。
RL是时序决策框架,通常以一个片段(episode)为基础,即一定会包含终止的状态。在某时刻t,使用Q(st,a;w)来估计不同动作的未来预期回报,但是什么时候才会得到未来预期回报的真值(GroundTruth)呢?那显然得得等到这个片段结束才会知道真值,使用梯度下降来更新模型参数,这样效率就会比较低下。
能不能在片段没有结束之前进行更新模型参数呢?可以,因为经过了某些步数之后,获得了这部分奖励的真值,可以使用这部分的真值来更新最初的预测,即每一步都修正之前的预测,每一步都更新模型的参数。
回报Ut包含一定的递归属性:Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯=Rt+γUt+1。
把上面关于Ut的递归方程应用在DQN中:
Estimate of UtQ(st,a;w)≈E[rt+γ⋅Estimate of Ut+1Q(St+1,At+1;w)]
把求期望括号内的部分称为TD Target:
PredictionQ(st,a;w)≈ETD Target[rt+γ⋅Q(St+1,At+1;w)]
有了Prediction和Target,就可以构建常见的损失函数更新模型参数了,令:
yt=rt+γ⋅Q(st+1,at+1;wt)=rt+γ⋅amaxQ(st+1,a;wt)
通常称Prediction和Target的差为TD error δ,即δt=Q(st,at;wt)−yt。
损失函数即为:
L=21[Q(st,at;wt)−yt]2
梯度更新参数:
wt+1=wt−α⋅∂w∂Lw=wt
使用TD训练DQN的伪代码:
- 获得状态St=st,执行动作At=at
- 预测价值:qt=Q(st,at;wt)
- 求微分:dt=∂wt∂Q(st,at;wt)w=wt
- 环境提供下一个状态st+1和当前的奖励rt
- 计算TD Target:yt=rt+γ⋅amaxQ(st+1,a;wt)
- 使用梯度下降更新参数:wt+1=wt−α⋅(qt−yt)dt
Actor-Critic Method
Actor-Critic Method是Value-based和Policy-based的结合,即使用模型同时对策略函数π(a∣s;θ)和动作-价值函数Qπ(a,s;w)进行建模。在前面Policy Gradient的训练处已经提到使用模型来估计Q函数。
Actor指的是策略函数π(a∣s;θ),用来控制动作的输出,Critic指的是动作-价值函数Qπ(a,s;w),用来对采取的动作进行打分,两者同时训练,使得Agent对动作的预期回报的估计越来越准,也更有可能得到更好的动作:
Vπ(s)=a∑π(a∣s;θ)⋅Qπ(a,s;w)
Training Actor-Critic
同时训练策略函数π(a∣s;θ)和动作-价值函数Qπ(a,s;w),需要分别用到前面的TD和梯度上升,伪代码如下:
- 获得状态st
- 根据π(a∣s;θ)随机采样动作at
- 执行动作at,从环境中获得奖励rt,并转移到下一个状态st+1
- 使用TD更新Critic网络参数w
- 从π(⋅∣st+1;θ)采样动作a~t+1,但是并不执行a~t+1
- 使用Qπ(a,s;w)来计算:qt=Q(st,at;wt)和qt+1=Q(st+1,a~t+1;wt)
- 计算TD target: yt=rt+γ⋅qt+1
- 损失函数:L(w)=21[qt−yt]2
- 梯度下降更新参数:wt+1=wt−α⋅∂w∂L(wt)w=wt
- 使用policy gradient来更新参数θ
- 计算梯度: dθ,t=∂θ∂logπ(at∣st,θ)θ=θt
- 更新参数:θt+1=θ+β⋅qt⋅dθ,t
- 重复直到收敛
Policy vs Value vs Actor-Critic
| 方法 | 优点 | 缺点 |
|---|
| Policy-based | 1.直接优化策略函数,适合连续动作空间
2.支持随机策略(从策略函数中采样得到动作) | 1.高方差,训练不稳定
2.采样效率低(on-policy),收敛速度慢
3.可能陷入局部最优,对超参敏感 |
| Value-based | 1.采样效率高:经验回放复用样本
2.确定性策略,通过价值函数选择最佳动作
3.收敛性较好 | 1.无法处理连续动作空间
2.确定性策略函数灵活性差
3.Q-learning的max操作导致价值函数高估 |
| Actor-Critic | 1.结合Policy和Value方法,平衡探索与利用(随机/确定性策略)
2.低方差,Critic估计逼policy方法方差更低
3.可处理连续和离散动作空间 | 1.训练难度高,同时训练两个网络,调参难度大
2.Critic估计的误差可能误导Actor
3.依赖Critic估计的准确性 |
MISC
on-policy v.s off-policy
| 名称 | on-policy | off-policy |
|---|
| 定义 | 行为策略(生成数据的策略)和目标策略(正在被优化的策略)必须是同一个策略 | 行为策略和目标策略不是同一个策略 |
| 特性 | 1.必须用当前策略与环境交互(rollout)的数据使用策略更新
2.策略更新后之前的数据被扔掉,样本效率低 | 1.可复用历史数据,样本效率高
2.行为策略可以更自由(如更注重探索),而目标策略更注重优化
3.数据来自不同策略,需处理分布的差异 |
| 算法 | 典型算法:REINFORCE, SARSA, PPO | 典型算法:Q-Learnig, DQN, DDPG |
model-free v.s model-based
model-based方法:
- 显式地学习动态模型,即转移函数P(s′∣s,a)和奖励函数R(s,a),利用该模型进行规划(Planning),例如通过模拟环境预测未来状态,从而优化策略或价值函数
- 特点:依赖环境模型,通过模型生成的虚拟轨迹来辅助决策
- 典型算法:Monte Carlo Tree Search (MCTS)(如AlphaGo中的规划方法),Dyna-Q, PILCO
model-free方法:
- 不显式地学习动态模型,直接通过试错从经验中学习策略或价值函数,依赖与环境的实时交互数据,而非通过动态模型的预测
- 特点:不依赖动态模型,数据驱动,样本效率低,需要海量的交互数据;这也是目前主流的算法方向
- 典型算法:Q-Learning, DQN,REINFORCE, PPO,A3C